
Statistik - Sufficient statistics, vad är nyttan av den?
Såg detta i samband med följande exempel:
Låt och , där , då kan X distribution beskrivas med bernoulli och med MLE av log likelihood ger (2.7)

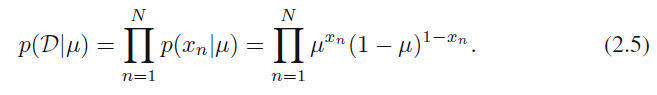


Då kallas i (2.6) för sufficient statistic för datan över distributionen eller något i stil med detta, eftersom enligt boken så beror log likelihood funktionen på N observationer x_n endast genom deras summa .
Det jag inte fattar är vad är nyttan med detta? I vilket fall kommer jag behöva använda datan för att utföra MLE i syfte att ta reda på , så det är inte så att datan förenklas eller försvinner eller något, bara att jag kanske abstraherar bort från att behöva tänka på att direkt behöva jobba med datan, då jag har någon sorts funktion som jag kan stoppa in data i och så får jag tillbaka något värdefullt som jag kan använda för log likelihood funktionen.
Min poäng är att jag hade fortfarande kunnat utföra MLE helt eller någon annan punktskattning eller annan estimeringsmetod för om jag bara arbetade på vanligt sätt och inte tänkte på sufficient statistics.

Oj, begreppet tillräcklig statistika är superviktigt, för mig var det värsta revolutionen i min förståelse för statistik när jag började förstå mig på tillräckliga statistikor.
Nu ska jag till jobbet och jag har mycket att göra idag men ska försöka ge ett utförligt svar till kvällen.
