
Jupyter Notebook Excel fil
Jag håller på med lite programmering i Python (är ny :)) och vill köra en excelfil i Notebooken. Jag har läst och tittat på olika videos för att kunna köra filen, jag fick följande:
Excelfilen innehåller Lufttemperatur, datum, tid, kvalitet osv. Hur bör jag göra?


Om det står "In [ ]:" så betyder det att cellen inte har exekverats. Kanske har du bara skrivit i den och sedan flyttat fokus till cell 9. Tryck "shift-enter" i cellen med "df=..." så exekveras den, eller kör programmet från början med "Run All" i cell-menyn.
Fortfarande fel :)
Jag gjorde som du skrev och fick syntaxfel:
Min fråga är, måste jag ladda upp excelfilen i notebooken, eller räcker det med att den är lagrad i datorn?
EDIT: I uppgiften står det: Ladda upp datafilen SMHI.csv i en python-miljö, exempelvis anaconda/jupyter notebook med dataanalysverktyget panda.
Beskriv översiktligt hur datamaterialet är strukturerat och vilka uppgifter som är
lagrade.
Syntaxfelen
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-15-a5274368b37a> in <module>
----> 1 df=pd.read_csv('SMHI.csv')
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
683 )
684
--> 685 return _read(filepath_or_buffer, kwds)
686
687 parser_f.__name__ = name
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in _read(filepath_or_buffer, kwds)
455
456 # Create the parser.
--> 457 parser = TextFileReader(fp_or_buf, **kwds)
458
459 if chunksize or iterator:
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in __init__(self, f, engine, **kwds)
893 self.options["has_index_names"] = kwds["has_index_names"]
894
--> 895 self._make_engine(self.engine)
896
897 def close(self):
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in _make_engine(self, engine)
1133 def _make_engine(self, engine="c"):
1134 if engine == "c":
-> 1135 self._engine = CParserWrapper(self.f, **self.options)
1136 else:
1137 if engine == "python":
~\Anaconda3\lib\site-packages\pandas\io\parsers.py in __init__(self, src, **kwds)
1915 kwds["usecols"] = self.usecols
1916
-> 1917 self._reader = parsers.TextReader(src, **kwds)
1918 self.unnamed_cols = self._reader.unnamed_cols
1919
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: [Errno 2] File b'SMHI.csv' does not exist: b'SMHI.csv'
Jag skulle tro att du måste ladda upp Excel-filen till notebook-servern. Det brukar gå bra med att dra-och-släppa.
Jag har gjort så, men filen laddas ned till datorn igen bara.
Det ska tydligen finnas en upload knapp.
https://tljh.jupyter.org/en/latest/howto/content/add-data.html

Om du kör notebooken på din dator måste filen ligga i samma mapp som notebooken ligger.
Sorry! Filen låg där men som pdf.. Men jag fick det att funka nu i alla fall!

Tillägg: 17 mar 2022 10:14
För att besvara: "Beskriv översiktligt hur datamaterialet är strukturerat och vilka uppgifter som är
lagrade."
Räcker det med att läsa av vad som står eller finns det kommando som ska användas här?
df.head() kan nog vara ett lämpligt kommando att använda
Jag har kommit fram till detta. Cellerna fungerar och jag får resultat.
Visa spoiler
import pandas as pd
df=pd.read_csv('SMHI.csv')
df
df.head()
df.tail()Men när jag skriver följande kod i cellen, får jag syntaxfel :((
meanLufttemperatur = df['Lufttemperatur'].mean()
print(meanLufttemperatur)Syntaxfel

Problemet verkar vara att du inte har någon kolumn som heter ”Lufttemperatur”. Jag vet inte hur det ser ut när du printar df.head(), men där borde stå vilka kolumner du har och vad de heter.
Jo, det existerar faktiskt :D

Nej det gör den inte. När du läst in filen har den läst in alla kolumner som en enda. Det ser ut som att din csv-fil använder ";" för att separera datan (jag ser det eftersom det är ; mellan Datum och Tid exempelvis). Prova att lägga till sep=";" som argument i read_csv och se om det blir annorlunda (det ska vara tydlig separation mellan kolumnerna när du skriver ut head())
Intressant! Nu har jag fått detta (se bild 1), Jag har försökt räkna ut medelvärdet på "Lufttemperaturen" och fick fram ett värde (dock utan enhet)
Men sen blir det knas när jag räknar ut standardavvikelsen. det står "input(*)" och får då ingenting printat. Jag tror att formeln är rätt skriven i alla fall.
Bild 1
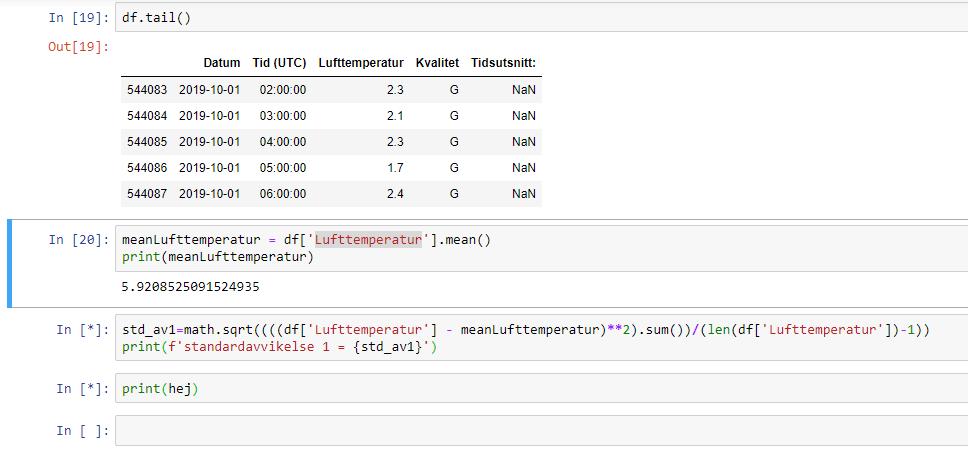
EDIT: Jag har lagt till några koder i cell input [1] och då fick jag till standardavvikelsen, men jag får syntaxfel. Vad är det?
Bild 2
Jag ser inte att du har något syntaxfel. I bild 2 ser jag bara en varning, vet inte vad den innebär tyvärr. Varför det inte verkar fungera i bild 1 vet jag inte heller, du verkar ju dock ha löst det
