
Högergränsvärdets definition

Jag har endast gjort detta steg: Men hur är meningen att fortsätta?
Men hur är meningen att fortsätta?

Det står inte vad högergränsvärdet är. Om t ex. f(x)—>8 när x—>1 fr höger så kan m inte väljas =1. Varje omgivning till 8 måste då innehålla alla f(x)-värden för alla x i någon högeromgivning till 1.
Fortsättningsvis: Låt m vara det givna högergränsvärdet och tillämpa definitionen.

Obs gränsvärdet behöver inte vara lika med m här.
Så du kan börja med att kalla gränsvärdet a.
, vilket ekvivalent kan skrivas .
Om a = 0 så erhåller vi direkt att att , så den sökta olikheten blir uppfylld om vi väljer m = .
Sedan skulle jag undersöka de två fallen a > 0 och a < 0.
Säg till om du kör fast.
PATENTERAMERA skrev:Obs gränsvärdet behöver inte vara lika med m här.
Så du kan börja med att kalla gränsvärdet a.
, vilket ekvivalent kan skrivas .
Om a = 0 så erhåller vi direkt att att , så den sökta olikheten blir uppfylld om vi väljer m = .
Sedan skulle jag undersöka de två fallen a > 0 och a < 0.
Säg till om du kör fast.
Kunde vi använda 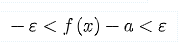 För att undersöka när a > 0 och a < 0?
För att undersöka när a > 0 och a < 0?
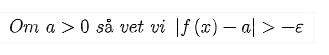 Detta kan vara helt fel tankesätt dock
Detta kan vara helt fel tankesätt dock
Det gäller ju även om a är mindre än noll.
Vi kan skriva om olikheten som
. Om a är större än noll så gäller det att .
Så vi har att
.
Kommer du vidare?
PATENTERAMERA skrev:Det gäller ju även om a är mindre än noll.
Vi kan skriva om olikheten som
. Om a är större än noll så gäller det att .
Så vi har att
.
Kommer du vidare?
Om a är mindre än noll är det då:
-a - epsilon > a - epsilon?
För a > 0 fick vi att
,
vilket är ekvivalent med , så i detta fall kan vi välja m = .
Låt nu a vara mindre än noll.
Vi har olikheten
.
Då a är mindre än noll så gäller det att . Vi får då
. Så vi kan välja m = .
Notera att vi kan sammanfatta alla fall ovan som att
. Så generellt kan vi välja m = .
Vi kan även härleda detta mha triangelolikheten: .
.
